From Proc Import to a Data Step with Regex
I find myself needing to import CSV files with a relatively large number of columns. In many cases, proc import works surprisingly well in giving me what I want. But sometimes, I need to do some work while reading in the file and it would be nice to just use a data step to do so, but I don’t want to type it in by hand. That’s when a combination of proc import and some regex substitution can come in handy.
For the first step, run a proc import, like this sample code that is provided by SAS Studio when you double click on a CSV file:
FILENAME REFFILE '/path/to/file/data.csv';
PROC IMPORT DATAFILE=REFFILE
DBMS=CSV
OUT=WORK.IMPORT;
GETNAMES=YES;
RUN;
If you run this code, you will see that SAS generates a complete data step for you. This is what the beginning of one looks like:
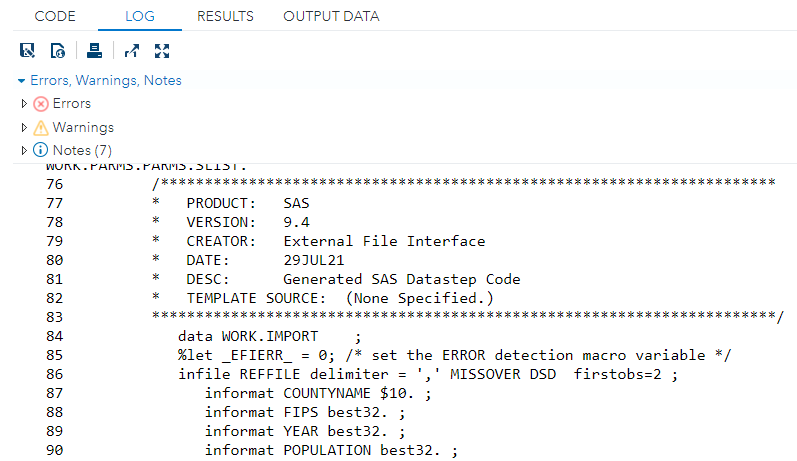
There will be be two lines for each variable, one giving the informat and one giving the format that SAS decided on. This will be followed by an input statement. You can copy that from the log into a text editor such as VSCode, but unfortunately the line numbering of the LOG will carry over. One convenient way of fixing this is to use regex search-and-replace. Each line starts with a space followed by 1-3 digits, followed by a variable number of spaces until the next word. To capture this I use ^\s\d{1,3}\s+ as my search term and replace with nothing. This will left align the whole data step, but this can be adjusted later.
At this point the data step can be saved as a SAS file or copied back over to the file you are working within SAS Studio, but I like to do one more adjustment. I really like using the attrib statement,
see documentation, because it allows me to see the informat, format, and label of a variable all in one place. So I use regex to re-arrange my informat statement into the beginnings of an attribute statement. Use the search term informat\s([^\s]+)\s([^\s]+)\s+; to capture each informat line and create two capture groups - the variable name as group 1 and the informat as group 2. If you use the replace code $1 informat=$2 format=$2, you will see the beginnings of an attribute statement. In this replacement scheme, each informat matches each format. This is fine for date and character variables, but you may want to adjust the display format for some of your numeric variables.
To clean this up, get rid of the format lines (you can search for ^format.+\n and replace with an empty replace to delete them), add the attrib statement below the infile and make sure to end the block of attributes with a semicolon, and indent your code as desired.
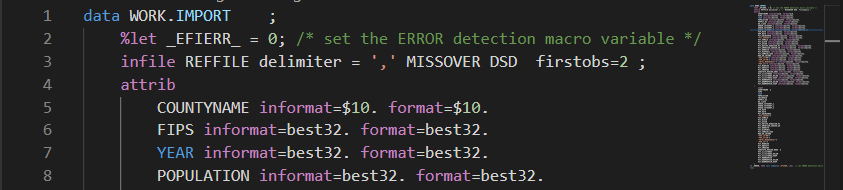
And there you have it! The beginning of a nicely formatted data step that you can start to work with.
D. Michael Senter
Research Statistician Developer
My research interests include data analytics and missing data.