Some Basic SQL Joins
A non-technical friend recently asked me for help with a merge problem. They had two separate data pulls of electronic medical records based on specific study parameters. The set of people in the database who fit the study parameters changed in between the data pulls, for example by having people age into our out of a study, or by having new diagnoses added to their records that cause them to either be newly included or excluded. Let’s call the older data set A and the newer data set B. The goal was to get all those entries from B that don’t also show up in A. The data sets were pulled by a staff data scientist at that company who, despite their title, said they couldn’t figure out how to remove those entries from B that were already in A. Barring any special circumstances, this is a fairly standard problem so let’s look at a couple of tools we could use to solve it.
Let’s start with some made-up sample data:
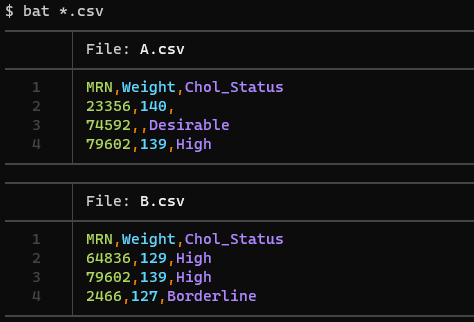
The MRN here stands for “medical record number,” a common unique identifier present in clinical data sets. Each of our data sets has three rows, but only one row is shared between both - that associated with MRN 79602. We could theoretically merge on multiple columns or coalesce data if we think some missing fields might have been updated in the meantime, but for purposes of this example we’ll keep it simple and just merge on the MRN.
SQL Merge Types
There are four basic types of merge: left join, right join, outer join, and inner join. There’s also the cross join but that one shows up less frequently in my experience. A picture speaks a thousand words, so here’s a Venn diagram illustrating the idea behind these joins.
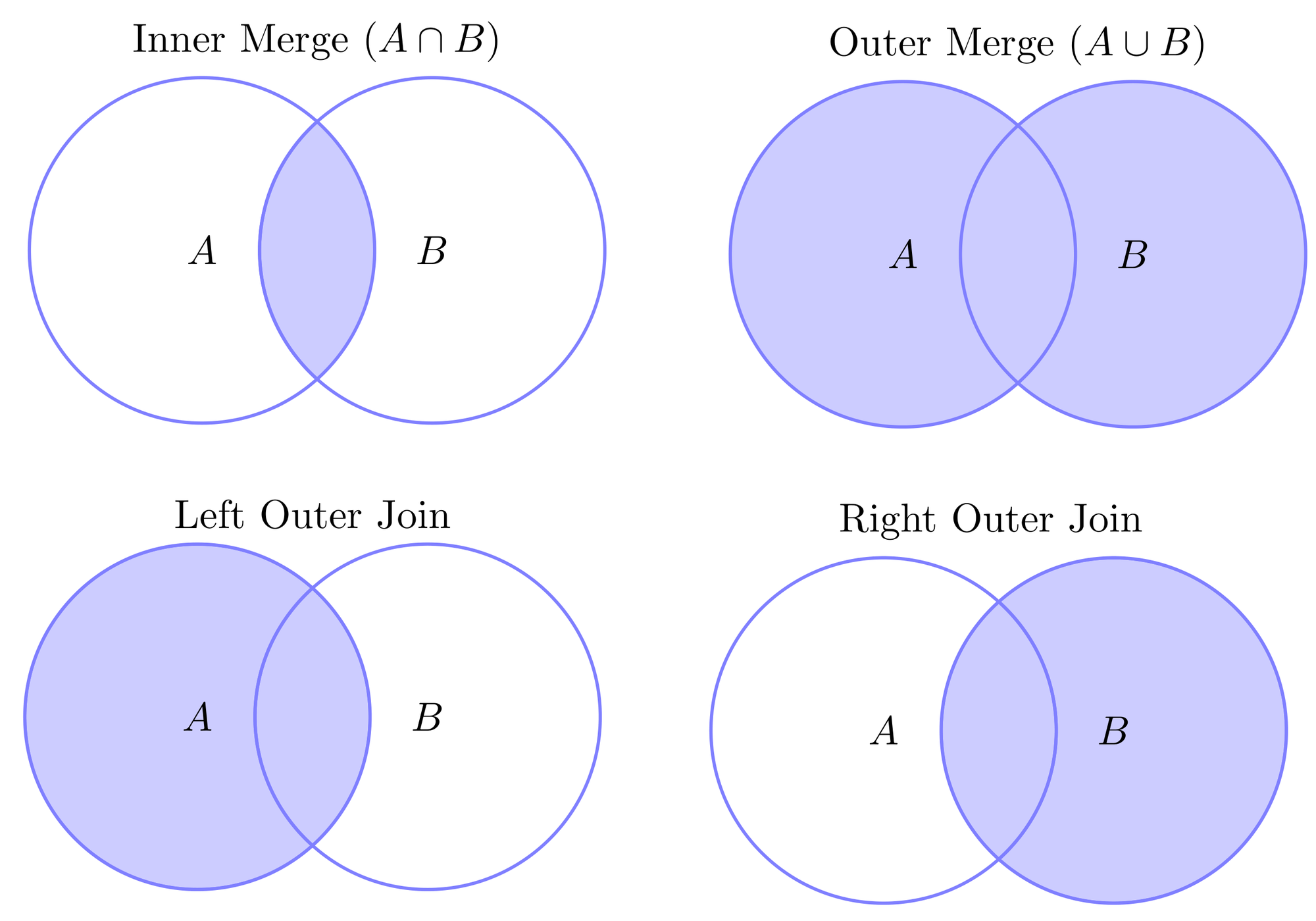
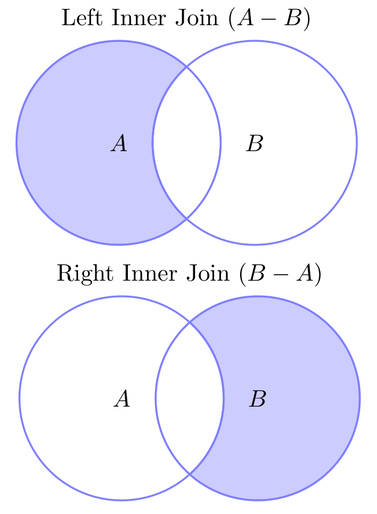
In our case, we actually want left/right “inner” or “exclusive” joins, like this:
Implementations
I figured I would go over three basic tools: SAS, SQL, and Pandas.
Only in A
For starters, we want all entries in $A$ that are not also in $B$. In set notation that is the set denoted $A-B$ (sometimes $A\backslash B$). Merges like this is what SQL excels at, so let’s see the SQL statment first:
create table res1 as
select A.* from
A left join B
on A.MRN=B.MRN
where B.MRN is NULL;
This should run in any typical SQL implementation, including PROC SQL in SAS and SQLite3. We expect the following table as output:
| MRN | Weight | Chol_Status |
|---|---|---|
| 23356 | 140 | |
| 74592 | Desirable |
To do a left outer join instead, we would just omit the where clause. We could do the same with a data step merge statement, but unlike SQL this would assume our input data sets are sorted by the merge key:
data res1;
merge A (IN = X) B (IN=Y);
by MRN;
If X and not Y;
run;
Pandas' merge statement allows for the creation of an indicator variable, similar to the in keyword used in the SAS data step merge. That indicator will tell us if the particular row is present in both the left and the right tables (value both), or just in one of them (values left_only and right_only). We can then query on that indicator variable to subset:
res1 = (pd.merge(A, B, how='outer', indicator=True)
.query('_merge=="left_only"')
.drop('_merge', axis=1))
Only in B
Same idea, but reversed: $B-A$. The implementation is identical except that we are using a right join instead:
create table res2 as
select B.* from
A right join B
on A.MRN=B.MRN
where A.MRN is NULL;
Expected output:
| MRN | Weight | Chol_Status |
|---|---|---|
| 64836 | 129 | High |
| 2466 | 127 | Borderline |
It is interesting to note that SQLite, at least as of 3.37.2, still doesn’t support right joins, so if you’re using that you’ll just want to use the left join method above but switch the A and B around. The data step implementation is also straight forward:
data res2;
merge A (IN = X) B (IN=Y);
by MRN;
If Y and not X;
run;
as is the Pandas version:
res2 = (pd.merge(A, B, how='outer', indicator=True)
.query('_merge=="right_only"')
.drop('_merge', axis=1))
What’s in common?
Finally, you might be curious to see which rows both data sets have in common, that is $A \cap B$. That’s a simple inner join:
create table res3 as
select A.* from
A inner join B
on A.MRN=B.MRN;
Expected output:
| MRN | Weight | Chol_Status |
|---|---|---|
| 79602 | 139 | High |
In SAS:
data res3;
merge A (IN = X) B (IN=Y);
by MRN;
If X and Y;
run;
and in Pandas:
res3 = (pd.merge(A, B, how='outer', indicator=True)
.query('_merge=="both"')
.drop('_merge', axis=1))
And that’s it. All that’s left to do is to save the data in a format your customer or colleagues can work with and we’re done.
D. Michael Senter
Research Statistician Developer
My research interests include data analytics and missing data.