After reading a news article about teacher pay in the US, I was curious and wanted to look into the source data myself. Unfortunately, the source that was mentioned was a publication by the National Education Association (NEA) which had the data as tables embedded inside a PDF report. As those who know me can attest, I don’t like hand-copying data. It is slow and error-prone. Instead, I decided to use the tabula package to extract the information from the PDFs directly into a Pandas dataframe. In this post, I will show you how to extract the data and how to clean it up for analysis.
The Data Source
Several years worth of data are available in PDF form on the NEA website. Reading through the technical notes, they highlight that they did not collect all of their own salary information. Some states’ information is calculated from the American Community Survey (ACS) done by the Census Bureau - a great resource whose API I have covered in a different post. Each report includes accurate data for the previous school year, as well as estimates for the current school year. As of this post, the newest report is the 2020 report which includes data for the the 2018-2019 school year, as well as estimates of the 2019-2020 school year.
The 2020 report has the desired teacher salary information in two separate locations. One is in table B-6 on page 26 of the PDF, which shows a ranking of the different states’ average salary in addition to the average salary:
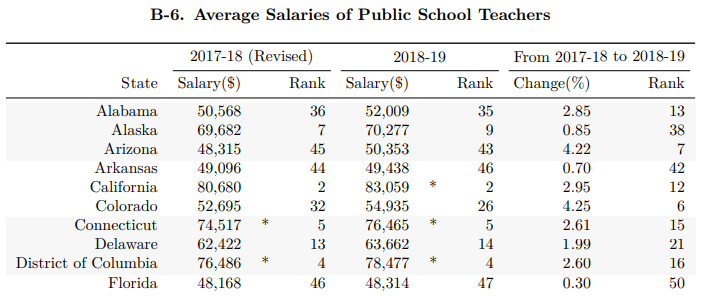
A second location is in table E-7 on page 46, which gives salary data for the completed school year as well as different states’ estimates for the 2019-2020 school year:
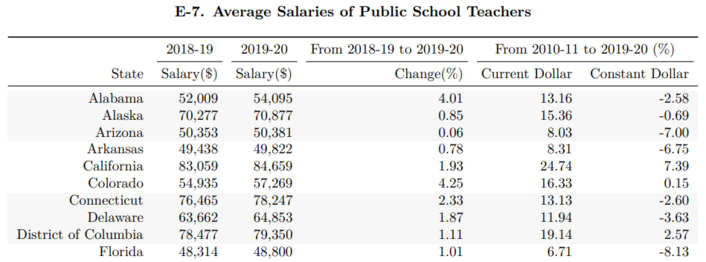
Note that table E-7 lacks the star-annotation marking NEA estimated values. This, and the lack of the ranking column, makes Table E-7 easier to parse. In the main example below, this will be the source of the five years of data. I will however also show how to parse table B-6 at the end of this post for completion.
Loading the Data
As of October 2020, the NEA site has five years worth of reports online. Unfortunately, these are not labeled consistently for all five years. Similarly the page numbers differ for each report. Prior to the 2018 report, inconsistent formats were used for the tables which require previous years to be parsed separately from the newer tables. For this reason, I’ll make a dictionary for the 2018-2020 reports only, which will simplify the example below.
report = {
'2020' : {
'url' : "https://www.nea.org/sites/default/files/2020-10/2020%20Rankings%20and%20Estimates%20Report.pdf",
'page' : 46,
},
'2019' : {
'url' : "https://www.nea.org/sites/default/files/2020-06/2019%20Rankings%20and%20Estimates%20Report.pdf",
'page' : 49,
},
'2018' : {
'url' : "https://www.nea.org/sites/default/files/2020-07/180413-Rankings_And_Estimates_Report_2018.pdf",
'page' : 51,
},
}
We can now use dictionary comprehension to fill in a dictionary with all the source tables of interest. We will be using the tabula package to extract data from the PDFs. If you don’t have it installed, you can use pip install tabula-py to get a copy. The method that reads in a PDF is aptly called read_pdf. Its first argument is a file path to the PDF. Since we want to use a URL, we will use the keyword argument stream=True and then name the specific page in each PDF that contains the information we are after. By default, read_pdf returns a list of dataframes, so we just save the first element from the list, which is the report we are interested in.
Note: if you are using WSL, depending on your settings, you may get the error Exception in thread "main" java.awt.AWTError: Can't connect to X11 window server using 'XXX.XXX.XXX.XXX:0' as the value of the DISPLAY variable. error when running read_pdf. This is fixed by having an X11 server running.
import tabula
import pandas as pd
source_df = {year : tabula.read_pdf(report[year]['url'], stream=True, pages=report[year]['page'])[0]
for year in report.keys()}
And that’s it in principle. How cool is that! Of course, we still need to clean our data a little bit.
Cleaning the Data
Let’s take a look at the first and last few entries of the 2020 report:
pd.concat([source_df['2020'].head(),
source_df['2020'].tail()])
| Unnamed: 0 | 2018-19 | 2019-20 | From 2018-19 to 2019-20 | From 2010-11 to 2019-20 (%) | |
|---|---|---|---|---|---|
| 0 | State | Salary($) | Salary($) | Change(%) | Current Dollar Constant Dollar |
| 1 | Alabama | 52,009 | 54,095 | 4.01 | 13.16 -2.58 |
| 2 | Alaska | 70,277 | 70,877 | 0.85 | 15.36 -0.69 |
| 3 | Arizona | 50,353 | 50,381 | 0.06 | 8.03 -7.00 |
| 4 | Arkansas | 49,438 | 49,822 | 0.78 | 8.31 -6.75 |
| 48 | Washington | 73,049 | 72,965 | -0.11 | 37.86 18.69 |
| 49 | West Virginia | 47,681 | 50,238 | 5.36 | 13.51 -2.28 |
| 50 | Wisconsin | 58,277 | 59,176 | 1.54 | 9.17 -6.02 |
| 51 | Wyoming | 58,861 | 59,014 | 0.26 | 5.19 -9.44 |
| 52 | United States | 62,304 | 63,645 | 2.15 | 14.14 -1.73 |
We see that each column is treated as a string object (which you can confirm by running source_df['2020'].dtypes) and that the first row of data is actually at index 1 due to the fact that the PDF report used a two-row header. This means we can safely drop the first row of every dataframe. We can also drop the last row of every dataframe since that just contains summary data of the US as a whole, which we can easily regenerate as necessary. So row indices 0 and 52 can go for all of our data sets.
for df in source_df.values():
df.drop([0, 52], inplace=True)
Next up I’d like to fix the column names. The fist column is clearly the name of the state (except in the case of Washington D.C.), while the next two columns give the years for which the salary information is given. Let’s rename the second and third columns according to the pattern Salary %YYYY-YY using Python’s f-string syntax.
for df in source_df.values():
df.rename(columns={
df.columns[0] : "State",
df.columns[1] : f"Salary {str(df.columns[1])}",
df.columns[2] : f"Salary {str(df.columns[2])}",
},
inplace=True)
source_df["2020"].head() # show the result of our edits so far
| State | Salary 2018-19 | Salary 2019-20 | From 2018-19 to 2019-20 | From 2010-11 to 2019-20 (%) | |
|---|---|---|---|---|---|
| 1 | Alabama | 52,009 | 54,095 | 4.01 | 13.16 -2.58 |
| 2 | Alaska | 70,277 | 70,877 | 0.85 | 15.36 -0.69 |
| 3 | Arizona | 50,353 | 50,381 | 0.06 | 8.03 -7.00 |
| 4 | Arkansas | 49,438 | 49,822 | 0.78 | 8.31 -6.75 |
| 5 | California | 83,059 | 84,659 | 1.93 | 24.74 7.39 |
Looks like we’re almost done! Let’s drop the unnecessary columns and check our remaining column names:
for year, df in source_df.items():
df.drop(df.columns[3:], axis=1, inplace=True)
print(f"{year}:\t{df.columns}")
2020: Index(['State', 'Salary 2018-19', 'Salary 2019-20'], dtype='object')
2019: Index(['State', 'Salary 2017-18', 'Salary 2018-19'], dtype='object')
2018: Index(['State', 'Salary 2017', 'Salary 2018'], dtype='object')
We can see that the column naming scheme in 2018 was different than in the previous reports. To make them all compatible for our merge, we’re going to have to do some more editing. Based on the other reports, it appears as though the 2018 report used the calendar year of the end of the school year, while the others utilized a range. This can easily be solved using regex substitution. We’ll do that now.
import re
for year, df in source_df.items():
if year != "2018":
df.rename(columns={
df.columns[1] : re.sub(r"\d{2}-", '', df.columns[1]),
df.columns[2] : re.sub(r"\d{2}-", '', df.columns[2]),
},
inplace=True)
# print the output for verification
print(f"{year}:\t{df.columns}")
2020: Index(['State', 'Salary 2019', 'Salary 2020'], dtype='object')
2019: Index(['State', 'Salary 2018', 'Salary 2019'], dtype='object')
2018: Index(['State', 'Salary 2017', 'Salary 2018'], dtype='object')
Now that everything works, we can do our merge to create a single dataframe with the information for all of the school years we have downloaded.
merge_df = source_df["2018"].drop(["Salary 2018"], axis=1).merge(
source_df["2019"].drop(["Salary 2019"], axis=1)).merge(
source_df["2020"])
merge_df.head()
| State | Salary 2017 | Salary 2018 | Salary 2019 | Salary 2020 | |
|---|---|---|---|---|---|
| 0 | Alabama | 50,391 | 50,568 | 52,009 | 54,095 |
| 1 | Alaska | 6 8,138 | 69,682 | 70,277 | 70,877 |
| 2 | Arizona | 4 7,403 | 48,723 | 50,353 | 50,381 |
| 3 | Arkansas | 4 8,304 | 50,544 | 49,438 | 49,822 |
| 4 | California | 7 9,128 | 80,680 | 83,059 | 84,659 |
Numeric Conversion
We’re almost done! Notice that we still have not dealt with the fact that every column is still treated as a string. Before we can use the to_numeric function, we still need to take care of two issues:
- The commas in the numbers. While they are nice for our human eyes, Pandas doesn’t like them.
- In the 2017 salary column, there appears to be extraneous white space after the first digit for some entries.
Luckily, both of these problems can be remedied with a simple string replacement operation.
merge_df.iloc[:,1:] = merge_df.iloc[:,1:].replace(r"[,| ]", '', regex=True)
for col in merge_df.columns[1:]:
merge_df[col] = pd.to_numeric(merge_df[col])
Now we’re done! We have created an overview of annual teacher salaries from the 2016-17 school year until 2019-20 extracted from a series of PDFs published by the NEA. We have cleaned up the data and converted everything to numerical values. We can now get summary statistics and do any analysis of interest with this data.
merge_df.describe() # summary stats of our numeric columns
| Salary 2017 | Salary 2018 | Salary 2019 | Salary 2020 | |
|---|---|---|---|---|
| count | 51.000000 | 51.000000 | 51.000000 | 51.000000 |
| mean | 56536.196078 | 57313.039216 | 58983.254902 | 60170.647059 |
| std | 9569.444674 | 9795.914601 | 10286.843230 | 10410.259274 |
| min | 42925.000000 | 44926.000000 | 45105.000000 | 45192.000000 |
| 25% | 49985.000000 | 50451.500000 | 51100.500000 | 52441.000000 |
| 50% | 54308.000000 | 53815.000000 | 54935.000000 | 57091.000000 |
| 75% | 61038.000000 | 61853.000000 | 64393.500000 | 66366.000000 |
| max | 81902.000000 | 84227.000000 | 85889.000000 | 87543.000000 |
Table B-6
As mentioned above, table B-6 in the 2020 Report presents slightly greater challenges. A lot of the cleaning is similar or identical, so I will not reproduce it in full. Instead, I have loaded a subsetted part of table B-6 and will show how this can be cleaned up as well. But first, let’s look at the first several entries:
| Unnamed: 0 | 2017-18 (Revised) | 2018-19 | |
|---|---|---|---|
| 0 | State | Salary($) Rank | Salary($) |
| 1 | Alabama | 50,568 36 | 52,009 |
| 2 | Alaska | 69,682 7 | 70,277 |
| 3 | Arizona | 48,315 45 | 50,353 |
| 4 | Arkansas | 49,096 44 | 49,438 |
| 5 | California | 80,680 2 | 83,059 * |
| 6 | Colorado | 52,695 32 | 54,935 |
| 7 | Connecticut | 74,517 * 5 | 76,465 * |
| 8 | Delaware | 62,422 13 | 63,662 |
We can see that there is an additional hurdle compared to the previous tables: the second column now contains data from two columns, both the Salary information as well as a ranking of the salary as it compares to the different states. For a few states, there is additionally a ‘*’ to denote values that were estimated as opposed to received. We can again use a simple regex replace together with a capture group to parse out only those values that we are interested in, while dropping the extraneous information using the code below.
b6.iloc[:,1:] = b6.iloc[:,1:].replace(r"([\d,]+).*", r"\1", regex=True)
And now we’re back to where we were above before we did the string conversion. This is what it looks like after also dropping the first row and renaming the columns:
| State | Salary 2018 | Salary 2019 | |
|---|---|---|---|
| 1 | Alabama | 50,568 | 52,009 |
| 2 | Alaska | 69,682 | 70,277 |
| 3 | Arizona | 48,315 | 50,353 |
| 4 | Arkansas | 49,096 | 49,438 |
| 5 | California | 80,680 | 83,059 |
| 6 | Colorado | 52,695 | 54,935 |
| 7 | Connecticut | 74,517 | 76,465 |
| 8 | Delaware | 62,422 | 63,662 |
From here on out, we can proceed as in the previous example.