The Census Bureau makes an incredible amount of data available online. In this post, I will summarize how to get access to this data via Python by using the Census Bureau’s API. The Census Bureau makes a pretty useful guide available here - I recommend checking it out.
API Basics
We can think of an API query of consisting of two main parts: a base URL (also called a root URL) and a query string. These two strings are joined together with the query character “?” to create an API call. The resulting API call can in theory be copy-and-pasted into the URL bar of your browser, and I recommend this when first playing around with a new API. Seeing the raw text returned in the browser can help you understand the structure of what is being returned. In the case of the Census Bureau’s API, it returns a string that essentially looks like a list of lists from a Python perspective. This can easily be turned into a Pandas dataset. Be aware that all values are returned as strings. You’ll have to convert number columns to numeric by yourself.
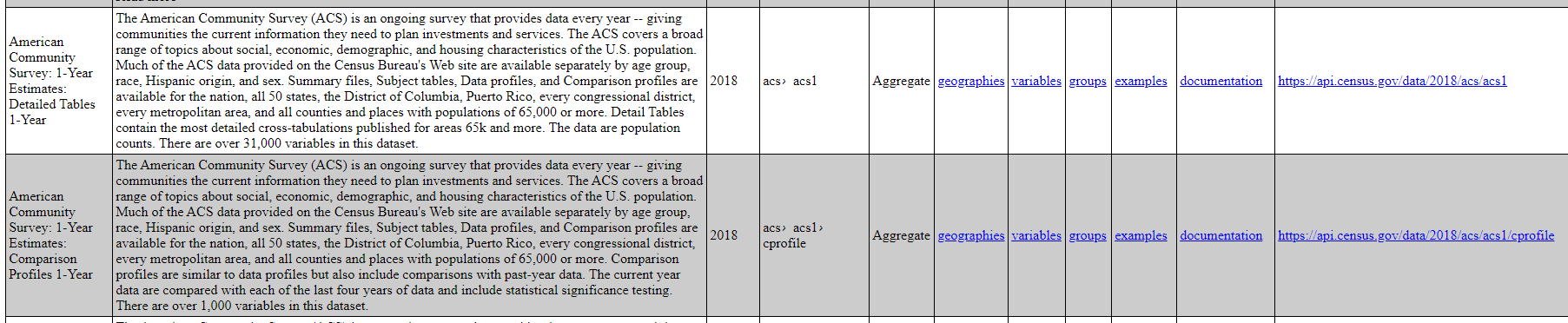
To get an overview of all available data sets, you can go to the data page which contains a long list of data sets. This data page is incredibly useful because it gives access to all of the information needed to build a correct API call, including the base URLs of all data sets and the variables available in each.
Building an the Base URL
Let’s build a sample API call for the 2018 American Community Survey 1-Year Detailed Table. While we could just copy the base URL from the data page, I like to assemble mine manually from its component parts. This makes it easier to write a wrapper for the API calls if you plan on scraping the same data from multiple years.
host_name = "https://api.census.gov/data"
year = "2018"
dataset_name = "acs/acs1"
base_URL = f"{host_name}/{year}/{dataset_name}"
Building the Query
Now that we have the base URL, we can work on building the query. For purposes of the Census Bureau, you will need two components: the variables of interest, which are listed after the get= keyword, and the geography for which you would like the data listed after the for= keyword. For certain subdivisions, like counties, you can specify two levels of geography by adding an in= keyword at at the end.
The ‘Get’ Variables
Since many of the data sets have a large amount of variables in them, it often makes sense to take a look at the “groups” page first. This page lists variables as groups, giving you a better overview of what data is available. This page is available at {base_URL}/groups.html. A complete list of all variables in the data set is available at {base_URL}/variables.html.
Let’s find some variables. The most basic variable we’d expect to find here is total population. We can find this variable in group “B01003”. The total estimate is in sub-variable “001E”, meaning that the variable for total population is “B01003_001E”. Let’s also get household income (group “B19001”) not broken down by race: “B19001_001E”. There is also median monthly housing cost (group B25105) with variable “B25105_001E”. Since the variable names can be a little difficult to parse, I recommend making a data dictionary as you prepare the list of variables to fetch.
data_dictionary = {
"B01003_001E" : "Total Population",
"B19001_001E" : "Household Income (12 Month)",
"B25105_001E" : "Median Monthly Housing Cost",
}
This way, the list of variables can easily be created from the data dictionary:
get_vars = ','.join(data_dictionary.keys())
Location Variables
Which geographic variables are available for a particular data set can be found {base_URL}/geography.html. The Census Bureau uses FIPS codes to reference the different geographies. To find the relevant codes, see here. Delaware for example has FIPS code 10 while North Carolina is 37. So to get information for these two states, we’d use for=state:10,37. You can also use ‘*’ as a wildcard. So to get all the states’ info you’d write for=state:*.
Subdivisions for similarly. To get information for Orange County (FIPS 135) in North Carolina (FIPS 37), you could write for=county:135 with the keyword in=state:37. Let’s get the information for Orange and Alamance counties in North Carolina.
county_dict = {
"001" : "Alamance County",
"135" : "Orange County",
}
county_fips = ','.join(county_dict.keys())
state_dict = {"37" : "North Carolina"}
state_fips = ','.join(state_dict.keys())
query_str = f"get={get_vars}&for=county:{county_fips}&in=state:{state_fips}"
The Complete Call
The complete API call can now be easily assembled from the previous two pieces:
api_call = base_URL + "?" + query_str
If we copy-and-paste this output into our browser, we can see the result looks as follows:

Making the API Request
We can make the API request with Python’s requests package:
import requests
r = requests.get(api_call)
And that’s it! We now have the response we wanted. To interpret the response as JSON, we would call the json method of the response object: r.json(). The result can then be fed into Pandas to generate our data set.
Reading the JSON into Pandas
We can use Pandas’ DataFrame method directly on our data, making sure to specify that the first row consists of column headers.
import pandas as pd
data = r.json()
df = pd.DataFrame(data[1:], columns=data[0])
We can then do any renaming based on the dictionaries we have created previously.
df.rename(columns=data_dictionary, inplace=True)
df['county'] = df['county'].replace(county_dict)
df['state'] = df['state'].replace(state_dict)
The last step is to make sure our numeric columns are interpreted as such. Since all of the requested variables are in fact numeric, we can use the dictionary of variables to convert what we need to numeric variables.
for col in data_dictionary.values():
df[col] = pd.to_numeric(df[col])
And that’s it! We’re now ready to work with our data.